Building a spam SMS classifier in Python

This Spring semester is my last semester of my Master's program, and I decided to save the best for last – Machine Learning!
As our final project, we needed to build our own classifier or app using Machine Learning, and I chose to build on work I had done in a previous semester and focus on SMS spam filtering.
There's a paper (that is now pretty old, but it's pretty clear the problem still stands) from 2006 that outlines the challenges around being able to detect spam in SMS because of the nature of SMS / text messages themselves.
- Text messages are short! It's a lot harder to build data models around short messages.
- In order to build a model, you need access to data, and in this case, text messages are hard to get (and most users don't want you to read their texts!).
- Spammers are really good at learning and changing their tactics.
Based on what I had read, I thought it might be fun to build a SMS spam classifier as my Machine Learning final project, to experience for myself how hard it can be to classify a short message as spam.
Can my Machine Learning algorithm perform better than people? Let's find out.
Step 1: Find a data source
Firsts things first, you have to get good data. I used kaggle to source my data, and I settled on a simple data source of text messages.
This data source was a collection of about 5k text messages, all which were labeled already as spam or ham.
I chose this data source because it was fairly simplistic, and it focused on the content of the text message, which is what the papers I had read in the past around SMS spam also did.
Step 2: Choose an algorithm
In this Machine Learning course, we learned about several algorithms, but I chose to focus on Bernoulli Naive Bayes, Multinomial Naive Bayes, and Logistic Regression, as these algorithms tend to work well with binary data, which is essentially what I had (i.e. is it spam or not).
I ran some tests to see which algorithm performed the best with my data set. With no text preprocessing, they all performed pretty well already with over 96% accuracy.
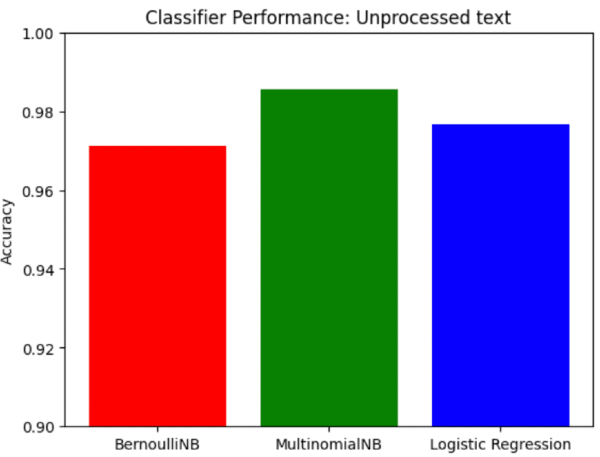
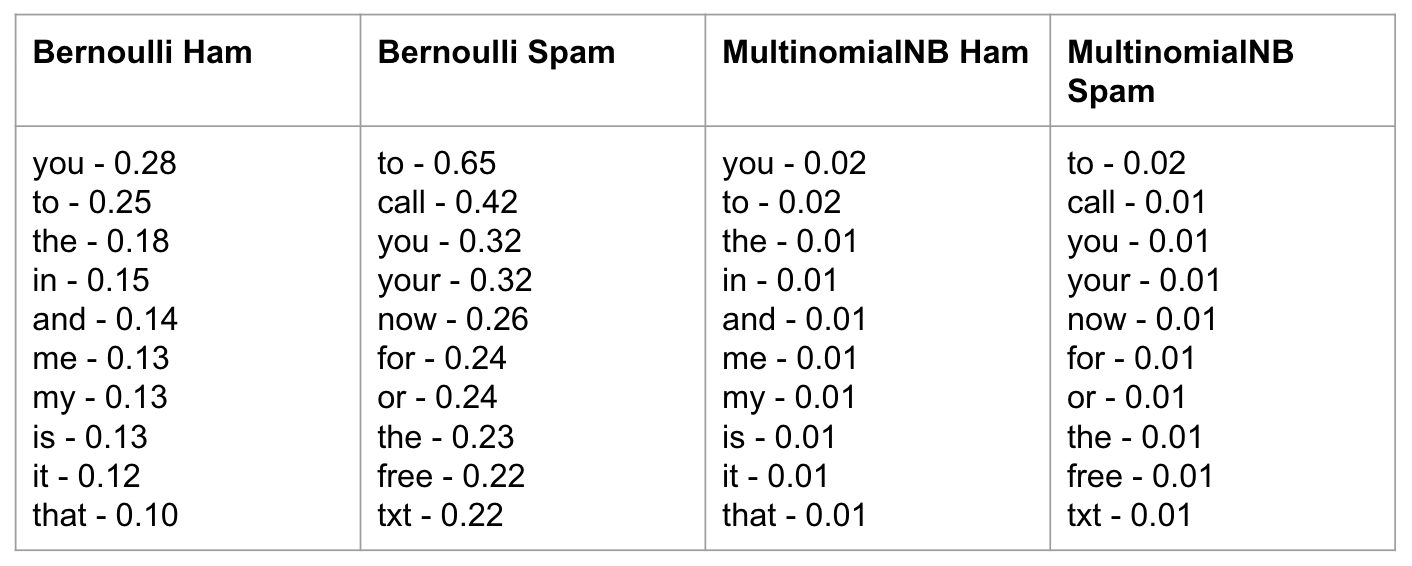
With no preprocessing of text, these are the top "features" (or words) that appear the most in Bernoulli and Multinomial Naive Bayes. You can see this doesn't tell us anything though.
Step 3: Let's do some text pre-processing
Pre-processing the text means removing words like you, to, the... you get the idea. These words, also known as stop words. They are common, appear a lot of text, and can muddy the waters, so to speak, so it's best to remove these.
The next thing you want to do is stemming, meaning take words like running, ran, and turn then into their stem, run. This makes it easier to spot patterns.
Luckily all of this is very easy to do in Python. I used the Natural Learning Tool Kit, or
nltk , to write my very simple text pre-processor:
def preprocess(sms):
text = sms.lower()
words = nltk.word_tokenize(text)
stop_words = set(stopwords.words('english'))
words = [w for w in words if w not in stop_words]
stemmer = PorterStemmer()
words = [stemmer.stem(w) for w in words]
return ' '.join(words)With this ready, let's train our classifiers again and see how they do with text pre-processing:
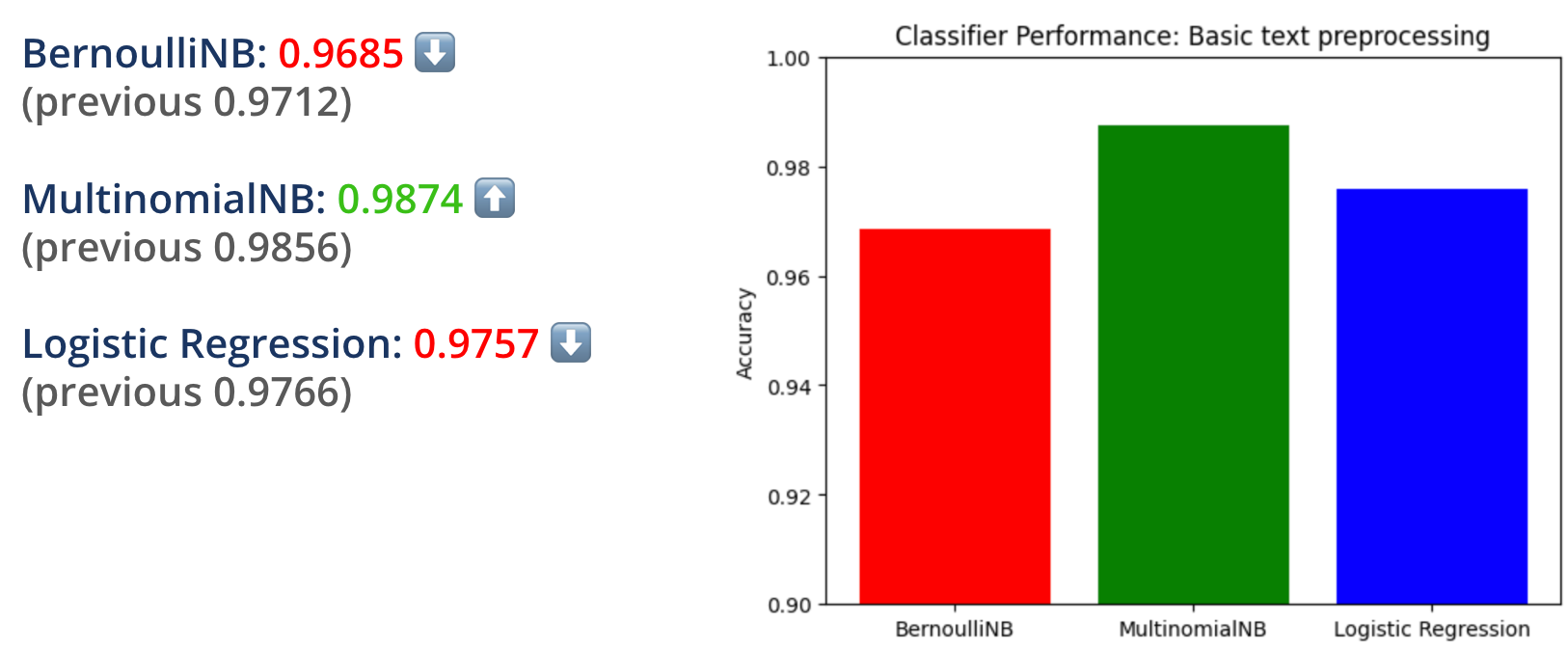
Turns out Bernoulli and Logistic Regression performed slightly worse than before, but Multinomial performed slightly better.
I wasn't too surprised at the results since not having any text pre-processing probably gave us some false positives.
Looking at the top words (aka features) with the basic text pre-processing is much more insightful now!

You can see, the words call, txt, free or claim are the top words in spam messages, signaling that SMS with calls to action tend to be spam. I highlighted www to show that URLs in SMS can also be a good indicator of possible spam. Let's see what happens when we remove the URLs from the text messages with pre-processing.
Step 4: Advanced text pre-processing goes too far
Based on my research around text pre-processing, it is common practice to remove things like URLs from the text, so I added this logic to my basic text pre-processor:
# remove URLs
words = re.sub(r'http\S+', '', words)
# remove digits
words = re.sub(r'\d+', '', words)This actually kind of tanked the performance of my classifiers:
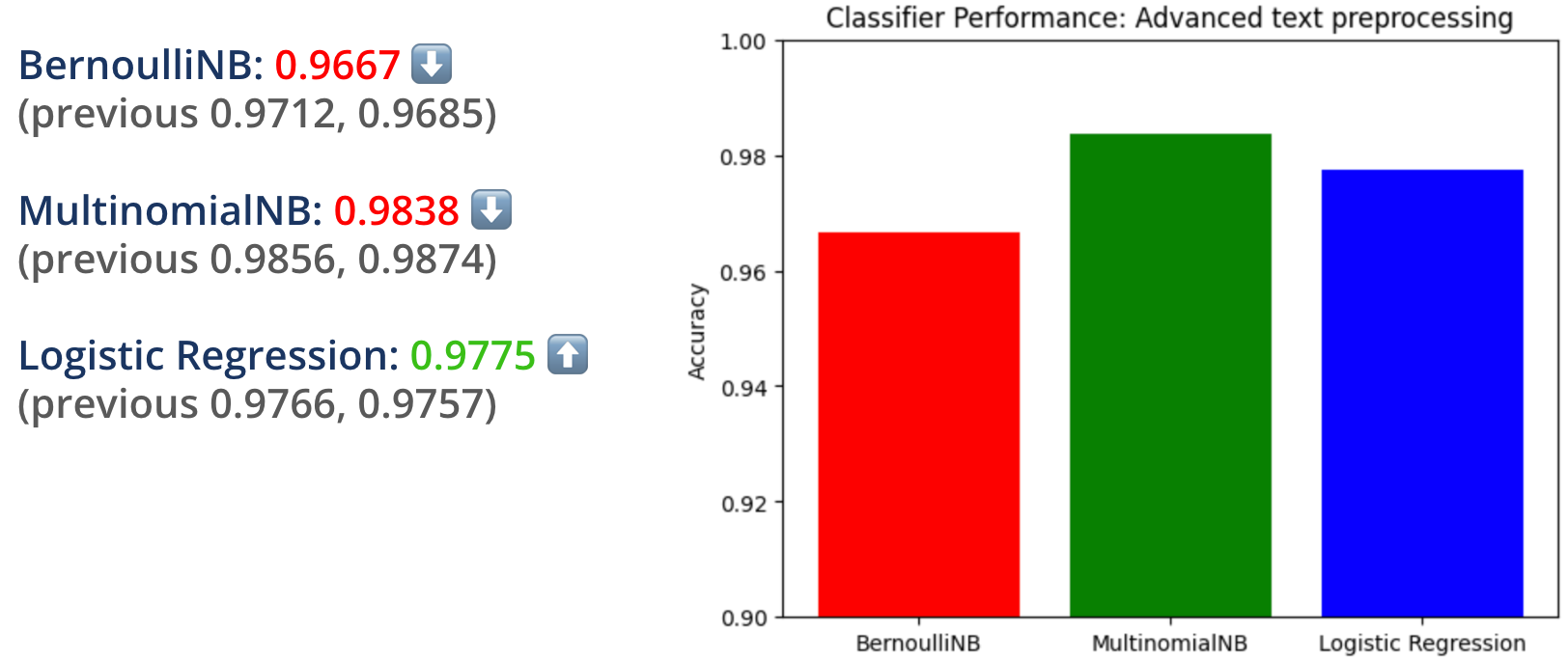
The top words or features didn't change much, except for the exclusion of www from the URLs.
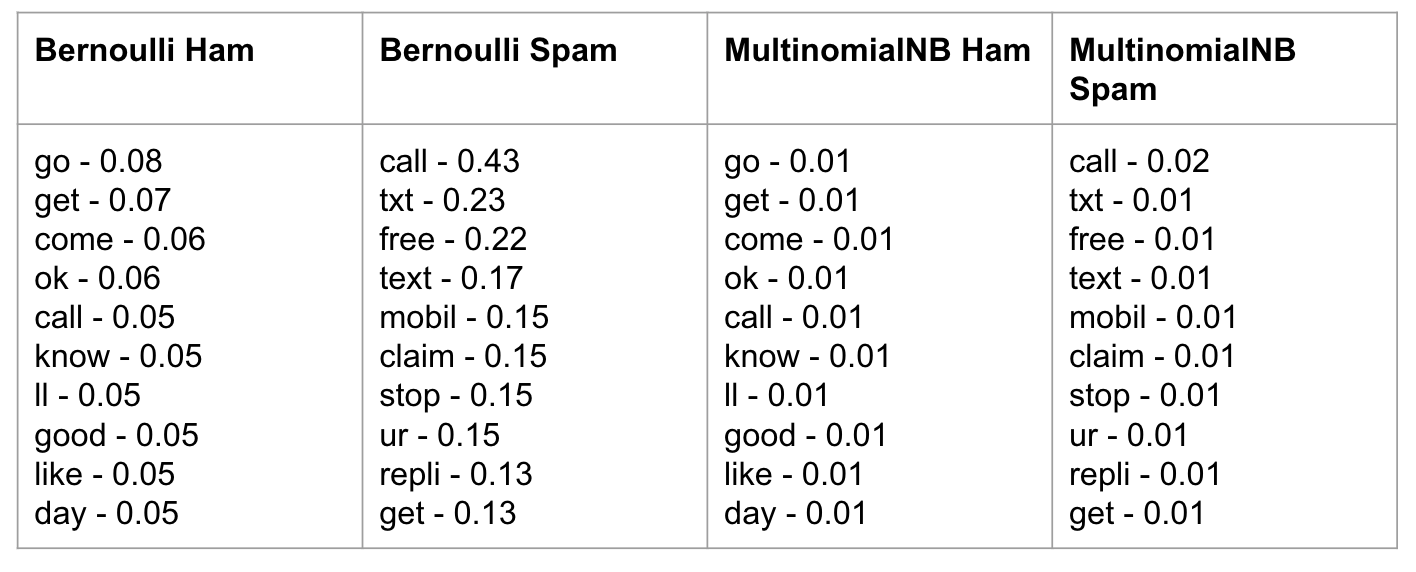
Since the biggest change was the exclusion of www from the top words, I came to the conclusion that including URLs in the text messages was actually really important for being able to detect whether a text message is spam, so I removed the code that removes URLs from my text pre-processor.
Step 5: Deploying it to the web!
I built a very simple Flask app and deployed it on Digital Ocean. I had never deployed an app before with any sort of Machine Learning, so I wanted to share how I did it here.
The biggest thing that helped me here is pickle. Pickle is a Python object serializer/deserializer, that can help you serialize/deserialize byte streaming data.
What I did was to train my model, and then export that to a pickle, which is then deserialized by the main app, and then used to feed the text message inputs from the user.
def load_model():
data = pd.read_csv(CSV_URL)
# Split the data into test and train
train_data = data.sample(frac=0.8, random_state=1)
test_data = data.drop(train_data.index)
# Vectorize the train and test data
vectorizer = CountVectorizer(binary=True, preprocessor=preprocess)
X_train = vectorizer.fit_transform(train_data['text'])
y_train = train_data['type']
X_test = vectorizer.transform(test_data['text'])
y_test = test_data['type']
# Train the model
clf = MultinomialNB()
clf.fit(X_train, y_train)
# Save the trained model to a file
joblib.dump(clf, 'classifier.pkl')
joblib.dump(vectorizer, 'vectorizer.pkl')Now in the main app, I load the model via pickle, and then use it in the app:
model.load_model()
clf = joblib.load('classifier.pkl')
vectorizer = joblib.load('vectorizer.pkl')
@app.route('/classify', methods=['POST'])
def classify():
sms = request.form['text']
if sms in prediction_cache:
prediction = prediction_cache[sms]
else:
preprocessed_sms = preprocess(sms)
vectorized_text = vectorizer.transform([preprocessed_sms])
prediction = clf.predict(vectorized_text)[0]
prediction_cache[sms] = prediction
return render_template('index.html', result=prediction, sms=sms)
This is simple, but it works!
The full source code of the app can be found here: https://github.com/cecyc/spam_or_ham
But does it work?
I took the app down from Digital Ocean because it costs money, but the app worked okay for what it was – an experiment!
The biggest thing I learned once I deployed the app and I had real users test it out, is that you need SO much more data.
Example:
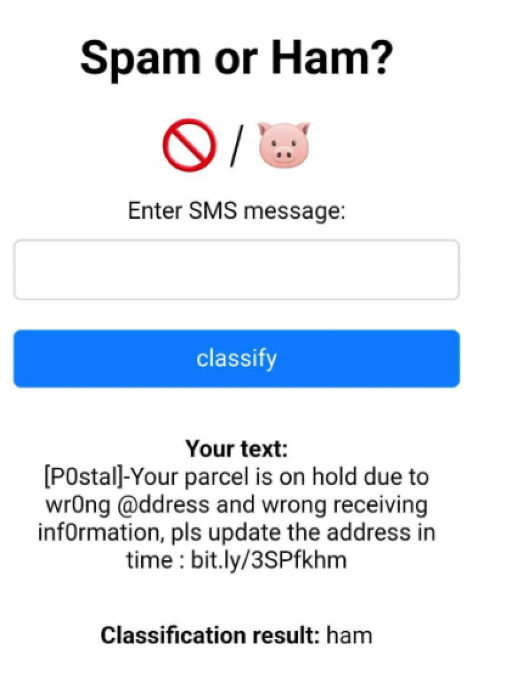
A friend of mine was able to easily fool my classifier by substituting digits and symbols for letters.
Also, the classifier only works on English words, so any foreign language is unsupported. This, again, comes down to my data source being all in English, which highlights the importance of having a large, varied data source.
Lessons learned
I was able to validate that classifying text as spam or ham is pretty difficult, especially given the limited data sets we have at our disposal.
That said, this was a fun project and I enjoyed how easily it was to put this all together with Python and Flask.